
[Work Log] Debugging training
There must be something wrong with the training marginal likelihood function, because the normal ML function pulls perturb_smoothing_variance lower, but training ML does not.
Can we refactor-out the training ML to test it independently of the training process?
Found a problem - perturbation scale was artificially constrained to be in (0,5). Training set perturb scale to 4.99996, unsurprisingly. I can't remember why I constrained it in this way, or why I chose 5 as the max, but it makex sense to relax it now. Setting to 50, with intent to remove constraint altogether. Still doesn't explain why perturb_smoothing_variance remains so high.
Test #1
Approach: plot tr_curves_ml vs. perturb_smoothing_variance. Compare against curve_tree_ml vs. perturb_smooth_variance
Results: Confirmed curves have different shape (ignoring offset). training ML plot:
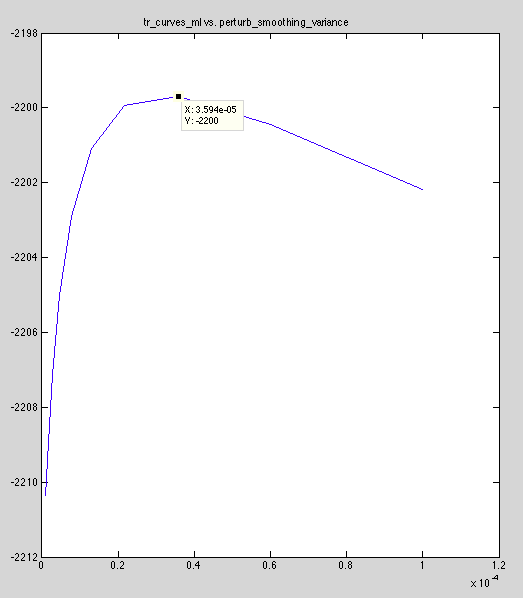
Reference ML plot:
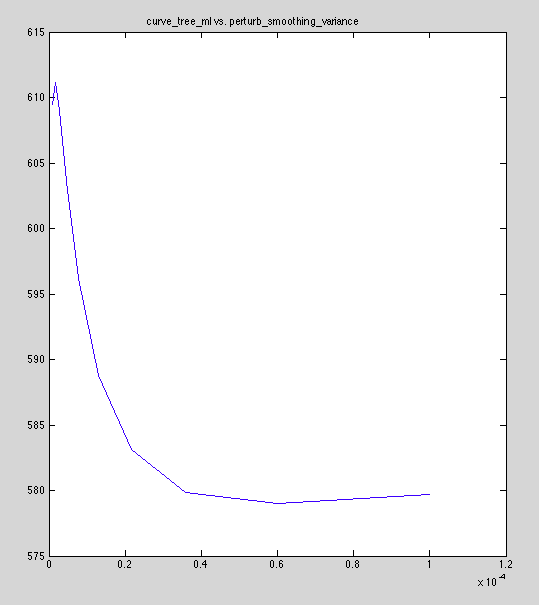
Is attachment the issue?
Test
Approach: re-run test #1 after detaching curves
Result: no qualitative change
Observations
Prior covariances seem equivalent. Likelihood covariances differ. Investigating... turns out noise variance was being handled wrongly in two places. Was dividing when I should have multiplied (cognitive issue: variance vs. precision); was using value instead of sqrt (cognitive issue: variance vs. standard deviation).
Bingo! Results are within a factor of 1.6e-5 of constant offset (for model #3)
Still getting differences with model #5.
prior is different in the perturb offset component -- differences are unstructured but large (on the order of +-5e-1). Numerical instability? Why here and not with model 3?
HUGE BUG in model #5: should have used 'independent' temporal model, not constant model.
Fixed, model #5 now agrees in both implementations (training and refernce).
Retraining
Running training now that we've worked out the apparent bugs.
perturb_scale is exploding to 49.999 (near max). unclear why. lets cap it lower for now, investigate later.
Capped scale to 10; it seems to settle lower, so we were probably just seeing a transient before. Possibly just return NaN in this case and it should take a smaller step.
Adding a new model
get_model_kernel get_model_kernel_derive get_base_covariance tr_curve_ml
Changes: * relaxed scale maximum * fixed bug in training marginal likelihood * fixed bug in model 5
Posted by Kyle Simek