
[Work Log] Troubleshooting excessive index drift in endpoints; fixing Hessian under variable transformation.
Getting bizarre spikes in indices during optimization. Confirmed that removing the spikes will improve ML, but there's a steep well between the two local minima as we reduce the index value:
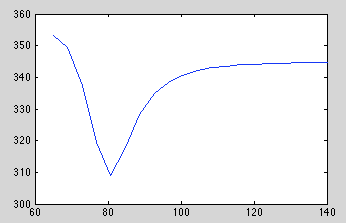
The index starts at a fairly reasonable initial value, so my only guess is that the Hessian is suggesting a large step which happens to step over the well.
I'm wondering if the hessian is screwy; or maybe it's just the transformation we're using. Optimizing raw indices doesn't exhibit this problem, but it is a problem in our our current approach of working with log differences to prevent re-ordering.
A prior over index spacing should probably prevent this; I'm hesitatnt to add the extra complexity at this point, considering the additional training and troubleshooting it would entail.
Should unit test the transformation.
...
Gradient looks okay.
On-diagonal elements have significant error!
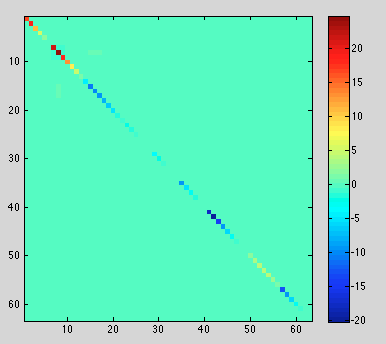
Actually, significant off-diagonal error, but on-diagonal dominates.
Since gradient is fine, and it uses the same jacobian, I'm guessing the problem isn't the jacobian transformation, but the hessian itself.
...
Confirmed. diagonal is (mostly) too high, error on order of 1e-3. Gradient error is around 1e-9.
Detective work. Look at diagonal of each Hessian term, compare to residual of diagonal, look for patterns.
...
Ugh, worst afternoon ever. Spent hours trying every trick in the book to track down the source of the error, including lots of time looking at the raw Hessian (it wasn't the raw Hessian). Finally found the bug: I formula I used for the chain rule for Hessians was wrong. In particular, it was missing a second term that (in my problem) corresponded to adding the transformed gradient to the diagonal. See Faa di Bruno's formula.
Total error is much reduced now, but not zero. around 0.1, instead of 20 before, new results:
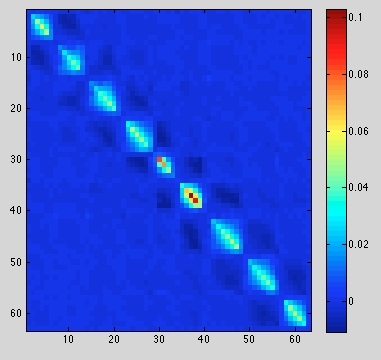
The norm-check is around 1e-4; very nice.
...
Re-running dataset 11 with hopes that we don't lose the global optimum. Interesting observation: optimization requires more iterations than before to converge. It seems a more conservative hessian results in smaller steps and is less likely Looks better:
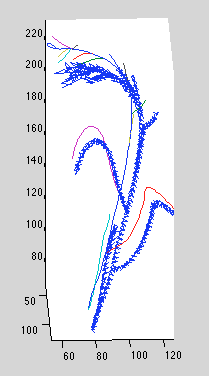
Notice we're still getting offset, but at least the reconstruction is qualitatively better that before. However, now we're getting a small loop at the top:

It seems to be caused by changing of index order between views. Needs some thought to best address.
...
Re-running on all datasets. Hopefully excessive index drift won't be too big an issue. Possibly an extra term to prevent drift far from initial points would be sensible.
Datasets 4,5 still drifts:
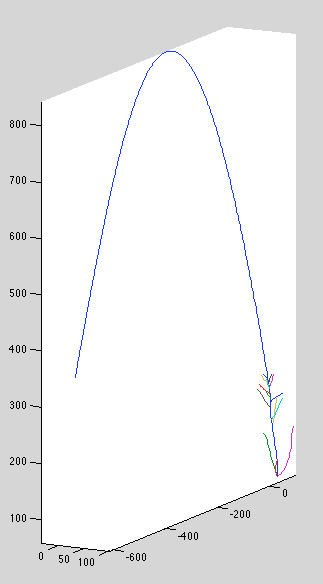
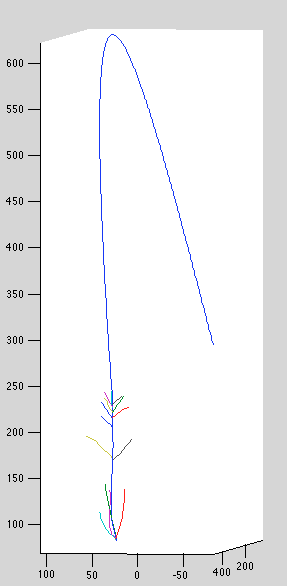
Datasets 7,9 have detached curves
Dataset 10, curve 2 (?) appears to have failed to prune
endpoint drift
It looks like interior points are confined by their neighbor points from drifting too far, but end points have no such constraint. After a small amount of drift, they're able to loop back on themselves and land directly on the backprojection line. It's surprising that the extra flexibility afforded by large spacing between indices doesn't cause marginal likelihood to suffer, since most of the new configurations are bad ones.
Considerations
- in-plone offset perturbation
- penalize excessive drift
- penalize excessive gaps (a-la latent GP model).
- penalize shrinkage.
Constraining offset perturbation
Constructing the offset perturbation variance so perturbations can only occur parallel to the image plane. Code is pretty straightforward:
cam_variance = blkdiag(repmat(sigma,N,N), repmat(sigma,N,N), zero(N,N));
camvariance(I,I) = cam_variance;
world_variance = R' * cam_variance * R
Where R is the rotation matrix from world to camera coordinates (i.e. from the extrinsic matrix).
The main difficulty here is logistical: throughout the codebase we store the prior variance in 1D format, and assume it will be expanded to 3D isotropically. Now we have a non-isotropic part of the prior, and we need to make sure it's included wherever the prior is needed.
Time for a real refactor. Need a 'get_K' function, instead of just taking the prior_K, adding the branch variance, and then adding the nonisotropic offset variance each time. Throw error if prior_K or branch_variance isn't ready. refactor strategy: search files for prior_K; those that call one_d_to_three_d shortly thereafter are refactor candidates, others will need further recursion to find the regactor point. But it all starts with prior_K. There shouldn't be that many leaf-nodes that use prior_K -- ML, gradient, reconstruction, WACV-spectific stuff...
Saturday
Refactoring to use nonisotropic perturb position covariance.
Refactoring construct_attachment_covariance will be difficult, because it works in 1D matrix format, but the new covariance must operate in 3D format. Will involve refactoring everything to 3D, re-index using block indexing, and double-check that noting relies on an independence assumption.
Better idea: apply perturb covariance after the fact. All connected curves will get the same covariance offset, so none of the special logic in construct_attachment_covariance is needed.
IDEA: use image position as an alternative index, and define a within-plane scaling covariance over it to account for poor calibration. Don't need to know any tree structure; shouldn't distort reconstruction positions since it's in-plane.
in-plane covariance adds to branch_index only. Thus, the only change needs to be in att_set_branch_index and/or detach. ... But what if we want index-specific in-plane covariance (e.g. scaling). Best to drop it into get_K, which will trickle into att_set_branch_index
Question: should each curve be allowed to shift in the image, or should the entire image be shifted as one? The former gives more flexibility, but possibly undeserved. One concern is that attaching two curves will eliminate that freedom, unfairly penalizing attachment. On the other hand, of all curves tend to shift in the same direction, the ML will increase after attaching them, promoting attachment. Will use per-curve shift for now.
Question: should shift be correlated between views? The theory is shift arises due to camera miscalibration.
Issue: sometimes the covariance matrix is gotten in other ways, e.g. when computing branch index, the parent's covariance is computed in-line.
TODO: recurse on
* construct_attachment_covariance