
[Work Log] KJB EM GMM
Still struggling with the EM GMM algorithm. Found/fixed one bug where responsibilities aren't initialized if NULL is passed to the function.
Ran overnight and it hadn't finished at the end. Found/fixed a bug where the entire @M element responsibility matrix is rescaled 2M times (once per point).
Getting rank-deficient errors. Looks like this is a result of the huge dataset; covariance matrix is divided by 1e6 (the number of soft-members of the cluster).
For now, hack by trying to thin the dataset. Long-term, adding a minimum offset to the emperical covariance seems to be the common solution.
Possibly normalizing the data would be good.
Added offset to covariance (command-line options and file-static variable already existed, just needed to add it to the full_GMM logic).
Added read_gmm.m matlab routine, and plotted along with scatter plot of data. Results look pretty good:
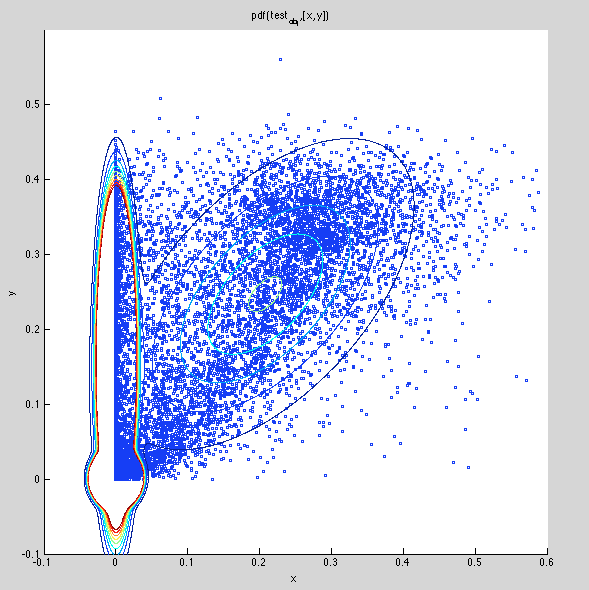
Moving trained gmm to ~/data/arabidopsis/training/bd_likelihood_gmm/blur_2.0.gmm
TODO
- increase spacing between reconstructed points
- get this running on cuda server
- re-train GMM on held-out dataset.
- implement matlab likelihood sampling
Open issues
- how to sync datasets on matlab and c++ server?
- Wacv multi-view reconstruction for training
- saving wacv to files for training
- fixing issues in wacv reconstructions
- evaluation methodology
- split/merge