
Index set bug fixed, marginal likelihood curves improved
Index Set Bug fixed
After fixing a problem with how index sets were estimated, the marginal likelihood (ML) curves are now much more sensible.
Here are two marginal likelihood curves using the old approach with two different smoothing sigmas.
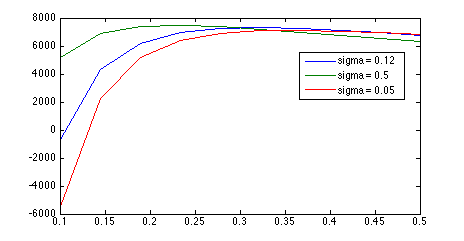
Notice how lowering the smoothing sigma \(\sigma_s\) causes the maximum ML to continuously improve, and results in a huge improvement when noise sigma \(\sigma_n\) is low. There are two implications of this:
- ML continuously improves as \(\sigma_s\) approaches zero
- As \(\sigma_s\) approaches zeros, the optimal \(\sigma_n \) approaches zero
We need to be able to use \(\sigma_n \) to control the cutoff for background curves, but this is not possible if ML is a monotonic function of \(\sigma_n\).
The problem arose from the fact that index-set spacing grew in proportion to curve-noise, whereas it should have stayed roughly constant. As a result, more noise made the curves look smoother, because the unobserved points seemed to be farther apart.
Obviously, this is the opposite of what we would want. I rewrote the "cleanup" algorithm so index sets are now computed from an estimate of the posterior curve, not from the maximum likelihood curve. This causes noise to be smoothed out of the curve before measuring the distance between points, so increasing noise will not significantly change the inter-point distance.
Here are the ML curves after the change.
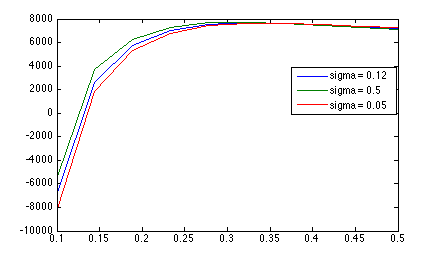
Some observations:
- The affect of changing \(\sigma_s\) is far less dramatic
- As \(\sigma_n\) approaches zero, the ML always drops below 0
- The position and value of the maximum is mostly unchanged, suggesting a "natural" noise-value that is independent of the smoothing value.
Point 2 is particularly important. These ML values are actually log ratios between the ML under this model and the ML under the "default" noise model. Values below zero indicate that the naive noise model is a better fit. The fact that we can adjust \(sigma_n\) to control the trade-off between the two models is promising, and suggests that this new model can, indeed, be discriminitive. Prior to these bugs, it was not clear that this was the case, because the background curve model always looked better than noise.
Point merging
One additional complication that arose was that after smoothing, many curve points at appeared at nearly the same position. As a result, the changes in the index set were very small and the resulting Gaussian Process covariance matrix became degenerate. I added some code that merges points that are too close to each-other, and updates the likelihood function and index set accordingly. My tests show that this causes a negligible decrease in the ML compared to the non-merged case, and eliminates the degeneracy problem in all the cases I encountered.
Smart Cleanup
During my investigations, I also rewrote the "cleanup" logic, which ensures that each point corresponds to the model curve exactly once. It originally did this by naively taking the first correpsondence, and I thought that the problematic results from above were caused by this. I wrote new logic that now chooses the best correspondence, i.e. the correspondence that results in the lowest error.
Summary, Next steps
The new code is in correspondence/corr_to_bg_likelihood.m, which now replaces the deprecated clean_bg_correspondence.m
Next steps
- Next test: can we distinguish BG curves from non-bg/foreground curves?
- Migrate this new logic to 3D curve model (clean_correspondence.m and maybe merge_correspondence.m)